SQLite#
Since SQLite adopts a dynamic type system, we infer type as follow:
If there is a declared type of the column, we derive the type using column affinity rules, code can be found here.
Otherwise we directly adopt the value’s type in the first row of the result (in each partition), which results in INTEGER, REAL, TEXT and BLOB.
If the first row of the result is NULL in the partition, try next partition. Throw an error if first rows of all partitions are NULL for a column.
SQLite Connection#
import connectorx as cx
db_path = '/home/user/path/test.db' # path to your SQLite database
conn = 'sqlite://' + db_path # connection token
query = 'SELECT * FROM `database.dataset.table`' # query string
cx.read_sql(conn, query) # read data from SQLite
Example on windows:
import connectorx as cx
import urllib
db_path = urllib.parse.quote("C:\\user\\path\\test.db") # url encode the path to your SQLite database
conn = 'sqlite://' + db_path # connection token
query = 'SELECT * FROM `database.dataset.table`' # query string
cx.read_sql(conn, query) # read data from SQLite
SQLite Type Mapping#
SQLite Type |
Pandas Type |
Comment |
|---|---|---|
INTEGER |
int64, Int64(nullable) |
declared type that contains substring “int” |
BOOL |
bool, boolean(nullable) |
declared type is “boolean” or “bool” |
REAL |
float64 |
declared type that contains substring “real”, “floa”, “doub” |
TEXT |
object |
declared type that contains substring “char”, “clob”, “text” |
BLOB |
object |
declared type that contains substring “blob” |
DATE |
datetime64[ns] |
declared type is “date” |
TIME |
object |
declared type is “time” |
TIMESTAMP |
datetime64[ns] |
declared type is “datetime” or “timestamp”, the format must follow |
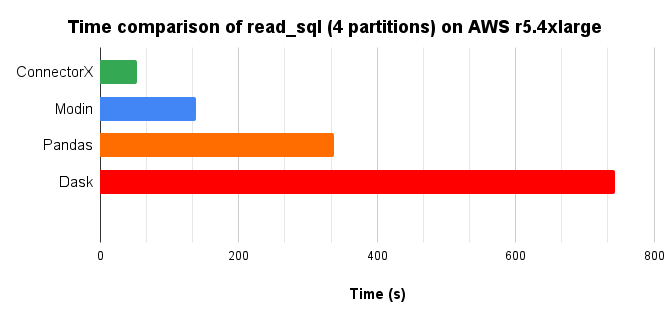
Performance (r5.4xlarge EC2 same instance)#
Turbodbc does not support read_sql on SQLite
Time chart, lower is better.
Memory consumption chart, lower is better.
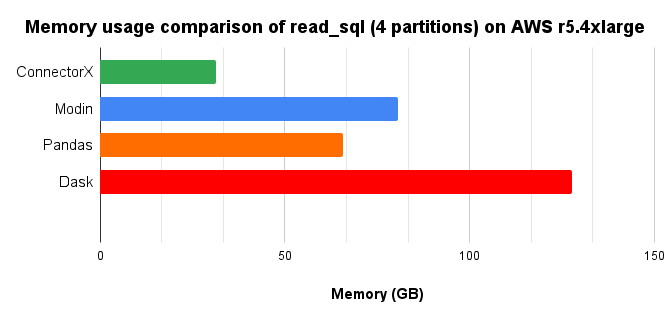
In conclusion, ConnectorX uses 2x less memory and 5x less time compared with Pandas.