Table of Contents¶
Assignment 2: Interactive Analytics¶
Overview¶
Real world is often dirty. Data scientists can spend 80% of their time on data cleaning without doing real analysis. Imagine you are a data scientists. When you get a dirty dataset and find it expensive to clean, what are you going to do?
If you can say "let's have a try of interactive analytics (e.g., interactive data cleaning, interactive machine learning, interactive visualization)", I will be so proud of what I have achieved in this course!In this assignment, you will learn how to use active learning to efficiently clean data. More specifically, you will be given a dirty dataset, which has many duplicate records. Your job is to identify the duplicate records. This is essentially an entity resolution problem. After completing this assignment, you should be able to answer the following questions:
- How to solve an entity resolution problem?
- How to implement an active learning algorithm?
Entity Resolution (ER)¶
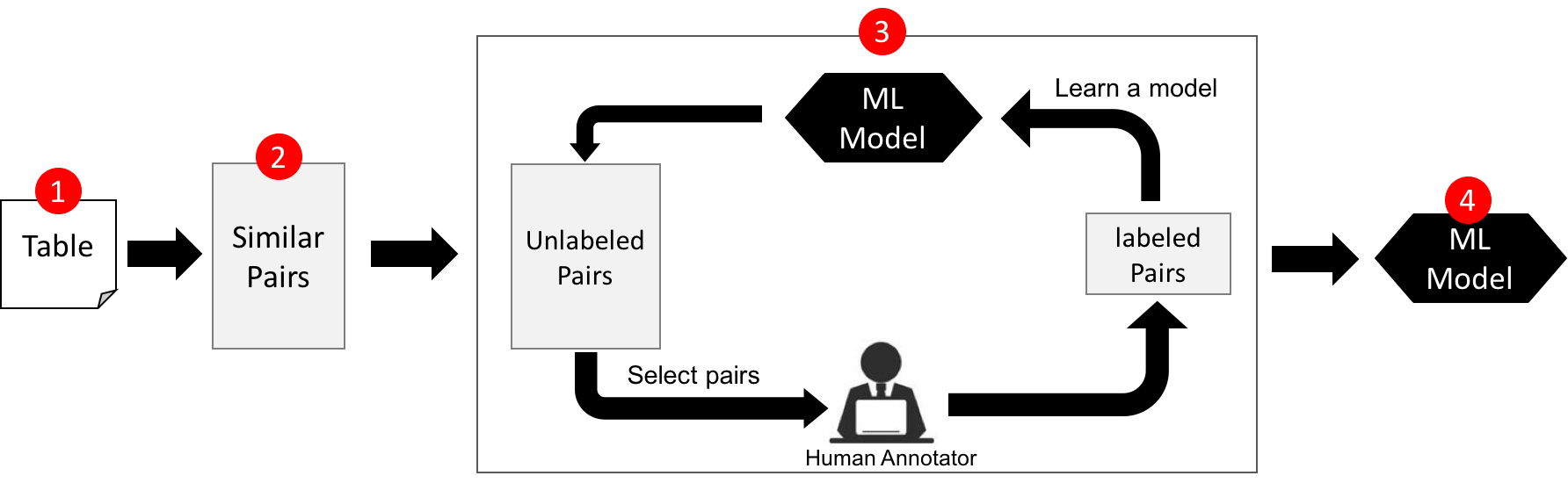
ER is defined as finding different records that refer to the same real-world entity, e.g., "iPhone 4-th Generation" vs. "iPhone Four". It is central to data integration and cleaning. The following figure shows the archtecture of an entity resolution solution. It consists of four major steps. I will provide you the source code for Steps 1, 2, 4. Your job is to implement Step 3.
Step 0. Upgrade to Reprowd 0.1.1¶
We added a few new features to Reprowd for this assignment. Please make sure to upgrade to Reprowd 0.1.1.
$ git clone https://github.com/sfu-db/reprowd.git
$ cd reprowd
$ python setup.py installYou can check the version through reprowd.__version__
>>> import reprowd
>>> print reprowd.__version__
0.1.1Step 1. Read Data¶
The restaurant data is in a CSV file. Here is the code to read it.
import csv
data = []
with open('restaurant.csv', 'rb') as csvfile:
reader = csv.reader(csvfile)
header = reader.next()
for row in reader:
data.append(row)
print "Num of Rows:", len(data)
print "Header:", header
print "First Row:", data[0]
print "Second Row:", data[1]
From this dataset, you will find many duplicate records. For example, the first two rows shown above are duplicate. You can check out all duplicate record pairs in the ground_truth.json file. This file will be used to evaluate your ML model in Step 4.
Step 2. Removing Obviously Non-duplicate Pairs¶
A naive implementation of entity resolution is to enumerate all $n^2$ pairs and check whether they are duplicate or not. Imagine the table has one million records. It will require to do $10^{12}$ pair comparisons, which is extremely expensive. Thus, the first challenge of entity resolution is how to avoid $n^2$ comparisons.
The basic idea is that among $n^2$ pairs, the majority of them look very dissimilar. Thus, we can run a similarity join algorithm to remove very dissimilar pairs, and assume that all of the removed pairs are non-duplicate. Note that similarity-join algorithms do not need to do $n^2$ comparisons with the help of inverted indices. You can refer to this paper (Sec 2) for more detail.
Here is the code. After running the code, you will get 678 similar pairs ordered by their similarity decreasingly.
from reprowd.utils.simjoin import *
def joinkey_func(row):
# concatenate 'name', 'address', 'city' and 'type', and
# tokensize the concatenated string into a set of words
return wordset(' '.join(row[1:]))
key_row_list = [(joinkey_func(row) , row) for row in data]
sj = SimJoin(key_row_list)
result = sj.selfjoin(0.4)
result.sort(key=lambda x: -x[2])
simpairs = [(row1, row2) for (key1, row1), (key2, row2), sim in result]
print "Num of Pairs: ", len(data)*(len(data)-1)/2
print "Num of Similar Pairs: ", len(simpairs)
print "The Most Similar Pair: ", simpairs[0]
Step 3. Active Learning¶
Given a set of similar pairs, what you need to do next is to iteratively train a classifier to decide which pairs are truly duplicate. We are going to use logistic regression as our classifier and use active learning to train the model.
Featurization¶
To train the model, the first thing you need to think about is how to featurize data. That is, transforming each similar pair to a feature vector. Please use the following code for featurization. Here, a feature is computed as a similarity value on an attribute. For instance, f1 is the edit similarity of the names of two restaurants.
from reprowd.utils.simjoin import *
# Use this function to transform each pair to a feature vector
def featurize(pair):
row1, row2 = pair
#cleaning
row1 = [alphnum(x.lower()) for x in row1]
row2 = [alphnum(x.lower()) for x in row2]
# features
f1 = editsim(row1[1], row2[1])
f2 = jaccard_w(row1[1], row2[1])
f3 = editsim(row1[2], row2[2])
f4 = jaccard_w(row1[2], row2[2])
f5 = editsim(row1[3], row2[3])
f6 = editsim(row1[4], row2[4])
return (f1, f2, f3, f4, f5, f6)
print "The feature vector of the first pair: ", featurize(simpairs[0])
Initialization¶
At the beginning, all the pairs are unlabeled. To initialize a model, we first pick up ten pairs and then use reprowd to label them. Please use the following code to do the initialization. Note that please set a distinct project name and short name to make the code work.
from reprowd.crowdcontext import *
from reprowd.presenter.text import TextCmp
# choose the most/least similar five pairs as initial training data
init_pairs = simpairs[:5] + simpairs[-5:]
def map_func(row_pair):
row1, row2 = row_pair
return {'obj1': zip(header, row1), 'obj2':zip(header, row2)}
cc = CrowdContext()
presenter = TextCmp().set_name("Finding Duplicate Resturants") \
.set_short_name("dup-resturant") \
.set_question("Are they the same restaurant?")
crowddata = cc.CrowdData(init_pairs, "active-ER") \
.set_presenter(presenter, map_func) \
.publish_task().get_result().quality_control("mv")
matches = []
nonmatches = []
for pair, label in zip(crowddata.data['object'], crowddata.data['mv']):
if label == 'Yes':
matches.append(pair)
else:
nonmatches.append(pair)
print "Number of matches: ", len(matches)
print "Number of nonmatches: ", len(nonmatches)
Interactive Model Training¶
Here is the only code you need to write in this assignment.
labeled_pairs = matches + nonmatches
unlabeled_pairs = [p for p in simpairs if p not in labeled_pairs]
batch_size = 2
iter_num = 5
#<-- Write Your Code -->
[Algorithm Description]. The algorithm trains an initial model on labeled_pairs. Then, it iteratively trains a model. At each iteration, it first applies the model to unlabeled_pairs, and makes a prediction on each unlabled pair along with a probability, where the probability indicates the confidence of the prediction. After that, it selects a batch of most uncertain pairs and publishes them to a crowdsourcing platform (e.g., http://ec2-54-200-84-187.us-west-2.compute.amazonaws.com:5000) using reprowd. After the published pairs are labeled, it updates labeled_pairs and unlabeled_pairs, and then retrain the model on labeled_pairs.
[Input].
labeled_pairs: 10 labeled pairs (by default)unlabeled_pairs: 668 unlabeled pairs (by default)iter_num: 5 (by default)batch_size: 2 (by default)
[Output].
model: A logistic regression model built by scikit-learn
[Requirements and Hints].
- Set n_assignments = 1.
- Note that the point of this assignment is not to evaluate the performance of crowd workers. So you don't have to collect labels from real-world crowd workers (e.g., mturk). Instead, you can do the labeling tasks by yourself or ask your friends for help.
- Please use sklearn to train the logistic regression model.
- Our interactive model training process is known as Active Learning.
- If you have any question about the assignment, please ask them in the Reprowd Google Groups.
- If you find a bug or want to add a new feature to reprowd, please follow the instruction at this page. You will get bonus points by making these contributions.
Last but not the least, even if you do not get a chance to file a bug or feature request, you can still make a contribution to the project by simply clicking the Star on Github.

Step 4. Model Evaluation¶
Precision, Recall, F-Score are commonly used to evaluate an entity-resolution result. After training an model, you can use the following code to evalute it.
import json
with open('ground_truth.json') as f:
true_matches = json.load(f)
def evaluate(identified_matches, true_matches):
n = 0
for (x, y) in identified_matches:
if [x, y] in true_matches or [y, x] in true_matches:
n += 1
precision = n*1.0/len(identified_matches)
recall = n*1.0/len(true_matches)
fscore = 2*precision*recall/(precision+recall)
return (precision, recall, fscore)
sp_features = np.array([featurize(sp) for sp in simpairs])
label = model.predict(sp_features)
pair_label = zip(simpairs, label)
identified_matches = []
for pair, label in pair_label:
if label == 1:
identified_matches.append(((pair[0][0], pair[1][0])))
precision, recall, fscore = evaluate(identified_matches, true_matches)
print "Precision:", precision
print "Recall:", recall
print "Fscore:", fscore
Submission¶
Download er.zip. Open er.ipynb and complete the code. Submit a zip package, named er-final.zip, with er.ipynb, restaurant.csv, ground_truth.json, and reprowd.db inside. Make sure others can rerun your code and reproduce your result.